Your streaming service knows your taste in movies better than most of your friends - not because someone studied you, but because a machine found patterns in your behavior it was never told to look for. That is unsupervised learning: algorithms that discover hidden structure in raw data with no labels, no guidance, and no predefined answers. It is how machines uncover what humans never thought to ask about.
What Makes This Tutorial Different
This is your entry point to unsupervised learning. We'll cover the fundamentals, help you understand the four core approaches (clustering, anomaly detection, dimensionality reduction, association rules), and guide you to dedicated deep-dive pages for specific techniques.
Abbreviations Used in This Article
AIArtificial Intelligence
MLMachine Learning
PCAPrincipal Component Analysis
t-SNEt-Distributed Stochastic Neighbor Embedding
UMAPUniform Manifold Approximation and Projection
LDALatent Dirichlet Allocation
ICAIndependent Component Analysis
What You'll Master in This Guide
01
What is Unsupervised Learning? - Learning from data without labels - finding hidden patterns
02
How Unsupervised Learning Works - The pattern discovery process explained step-by-step
03
Unsupervised vs Supervised Learning - Understanding the fundamental difference
04
The Four Core Approaches - Clustering, anomaly detection, dimensionality reduction, association rules
05
When to Use Unsupervised Learning - Problem suitability and decision framework
06
Clustering Fundamentals - Discovering natural groups in data
07
Anomaly Detection Basics - Finding unusual patterns and outliers
08
Dimensionality Reduction Essentials - Simplifying complex high-dimensional data
09
Association Mining Overview - Discovering relationships between items
10
Common Pitfalls - Top mistakes that derail unsupervised learning projects
11
Your Learning Journey - Roadmap through clustering, dimensionality reduction, and association rules
12
Frequently Asked Questions - Quick answers to common unsupervised learning questions
Unsupervised learning is the future of AI. Most of human and animal learning is unsupervised - we learn how the world works by observing it, not by being told what everything is. The real intelligence breakthrough will come when we crack unsupervised learning at scale. That's where the magic happens.
Yann LeCun
Chief AI Scientist at Meta, Turing Award Winner
What is Unsupervised Learning?
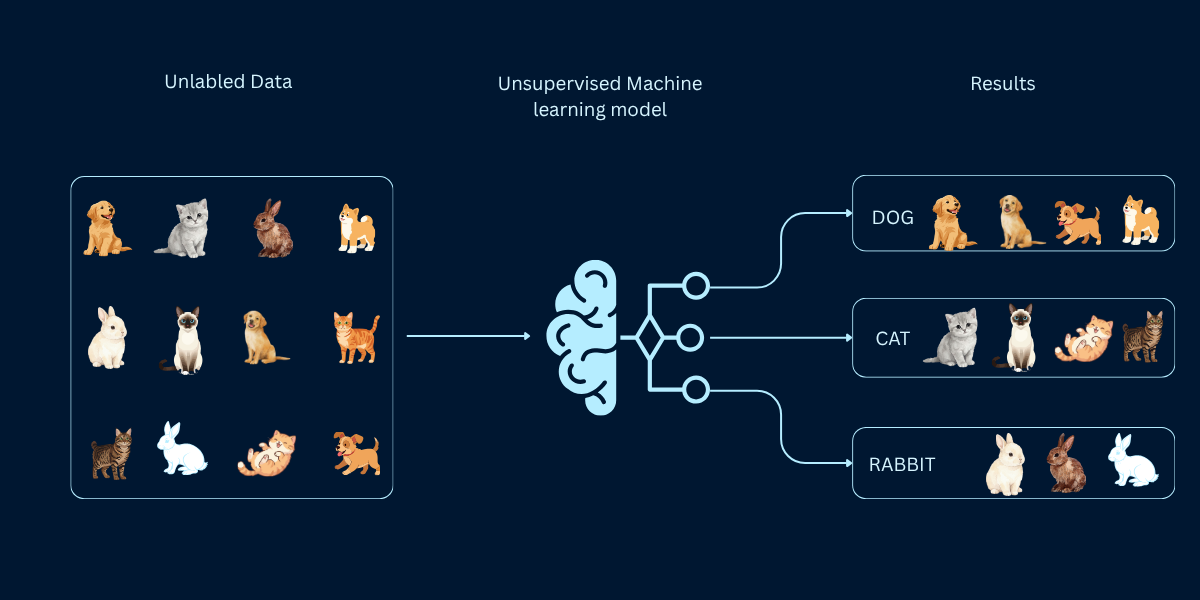
Imagine organizing thousands of photos on your computer without creating any folders or labels first. You just look at the images and naturally group similar ones together: vacation photos here, family gatherings there, pet pictures in another pile. That's essentially what unsupervised learning does—it finds patterns and groups in data without being told what categories to look for.
Unsupervised learning is fundamentally different from supervised learning. There are no "correct answers" provided during training. Instead, the algorithm explores the data on its own, discovering hidden structures, natural groupings, unusual patterns, and relationships that might not be obvious to human observers. This makes it both challenging and incredibly valuable for discovering insights you didn't even know existed.
How Unsupervised Learning Works
Unsupervised learning follows a fundamentally different process than supervised learning. Instead of learning from labeled examples, the algorithm explores the data to find patterns, structures, and relationships on its own. Here's the four-step process:
Data Collection: Gather raw, unlabeled data without any predefined categories or target variables. For example: customer purchase histories, website clickstreams, or sensor readings.
Pattern Discovery: The algorithm analyzes the data to identify hidden structures. This could be natural groupings (clustering), unusual data points (anomaly detection), essential features (dimensionality reduction), or item relationships (association rules).
Result Interpretation: The discovered patterns must be interpreted by domain experts to determine business relevance. Unlike supervised learning where accuracy is clear, unsupervised results require human validation and understanding.
Insight Application: Apply the discovered patterns to make decisions, generate recommendations, detect anomalies, or simplify data for further analysis.
The critical difference from supervised learning: there's no automatic way to validate that the patterns are correct or meaningful. Success depends on combining algorithmic pattern discovery with human domain expertise to interpret and act on the findings.
Unsupervised vs Supervised Learning: The Core Distinction
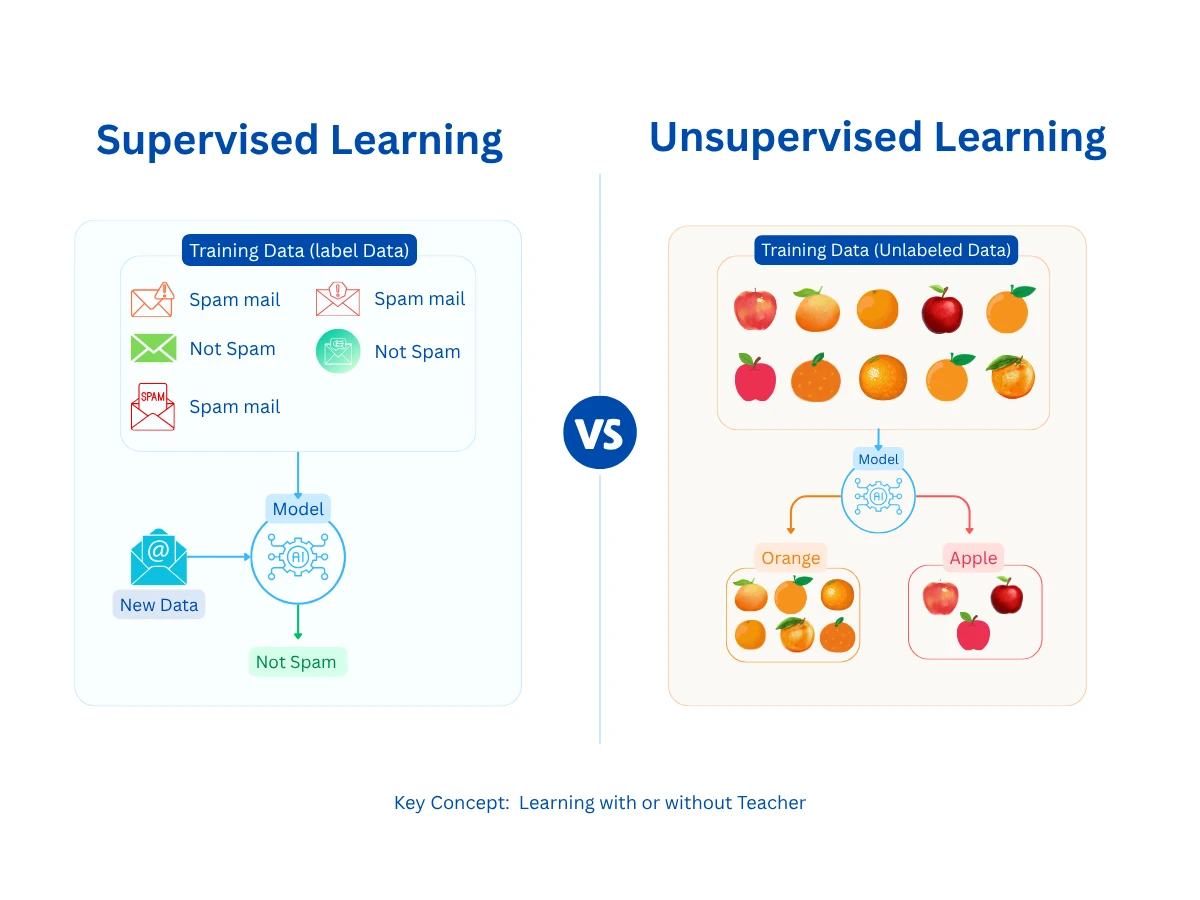
The fundamental difference between supervised and unsupervised learning lies in the training data. Supervised learning requires labeled examples with known outcomes (inputs and outputs), while unsupervised learning works with raw data to discover patterns without guidance.
Supervised vs Unsupervised Learning - The fundamental difference in how each approach uses (or doesn't use) labeled data during the learning process
Supervised vs Unsupervised Learning: Key Differences
Aspect
Supervised Learning
Unsupervised Learning
Training Data
Labeled examples with known outcomes
Unlabeled data without predefined categories
Goal
Predict outcomes for new data
Discover hidden patterns and structures
Learning Process
Learn from correct answers (supervision)
Explore data independently (no supervision)
Validation
Compare predictions to actual outcomes
Domain expert interpretation required
Common Uses
Spam detection, price prediction, diagnosis
Customer segmentation, fraud detection, data compression
Example Question
Is this email spam? (Yes/No)
What natural customer groups exist? (Unknown)
Success Metric
Prediction accuracy (clear measure)
Business value of discovered insights (subjective)
Source: Comparison framework based on standard machine learning taxonomy and practical applications documented in industry ML implementations
When to Use Which Approach
Use supervised learning when you have labeled data and want to predict specific outcomes. Use unsupervised learning when you have unlabeled data and want to discover unknown patterns, groupings, or relationships. Many real-world systems use both approaches together.
Interactive Deep Dive: This visual breakdown shows unsupervised learning's exploration process - discovering patterns in unlabeled data without predefined categories. Understanding the self-discovery approach and validation challenges helps you implement successful unsupervised learning systems.
Unsupervised Learning
15% of ML practitioners focus on clustering and pattern discovery
Simple Analogy
Like walking into a library where all the books are piled together with no shelves or signs. You start grouping them naturally - these look like novels, these feel like science books. No one told you the categories. You found them yourself.
Complete Breakdown
Discovering hidden patterns and structures in unlabeled data without predefined categories or guidance
How It Works
Algorithm receives data without any labels or answers
Discovers natural groupings, patterns, or anomalies in the data
Identifies relationships humans might not have noticed
Groups similar data points or detects unusual outliers
Real-World Examples
Customer segmentation (grouping similar customers automatically)Recommendation systems (finding users with similar tastes)Anomaly detection (spotting unusual transactions for fraud)Data compression (finding efficient ways to represent data)Topic modeling (discovering themes in document collections)
Best For
1Exploring data when you don't know what you're looking for
2Finding hidden patterns or customer segments
3Reducing data complexity (dimensionality reduction)
4Detecting outliers and anomalies
Limitations
1Results can be difficult to interpret or validate
2No clear "right answer" to measure accuracy against
3Requires domain expertise to make sense of discovered patterns
4Computational complexity can be high for large datasets
Unsupervised learning algorithms increasingly applied to uncover patterns in supply chain data
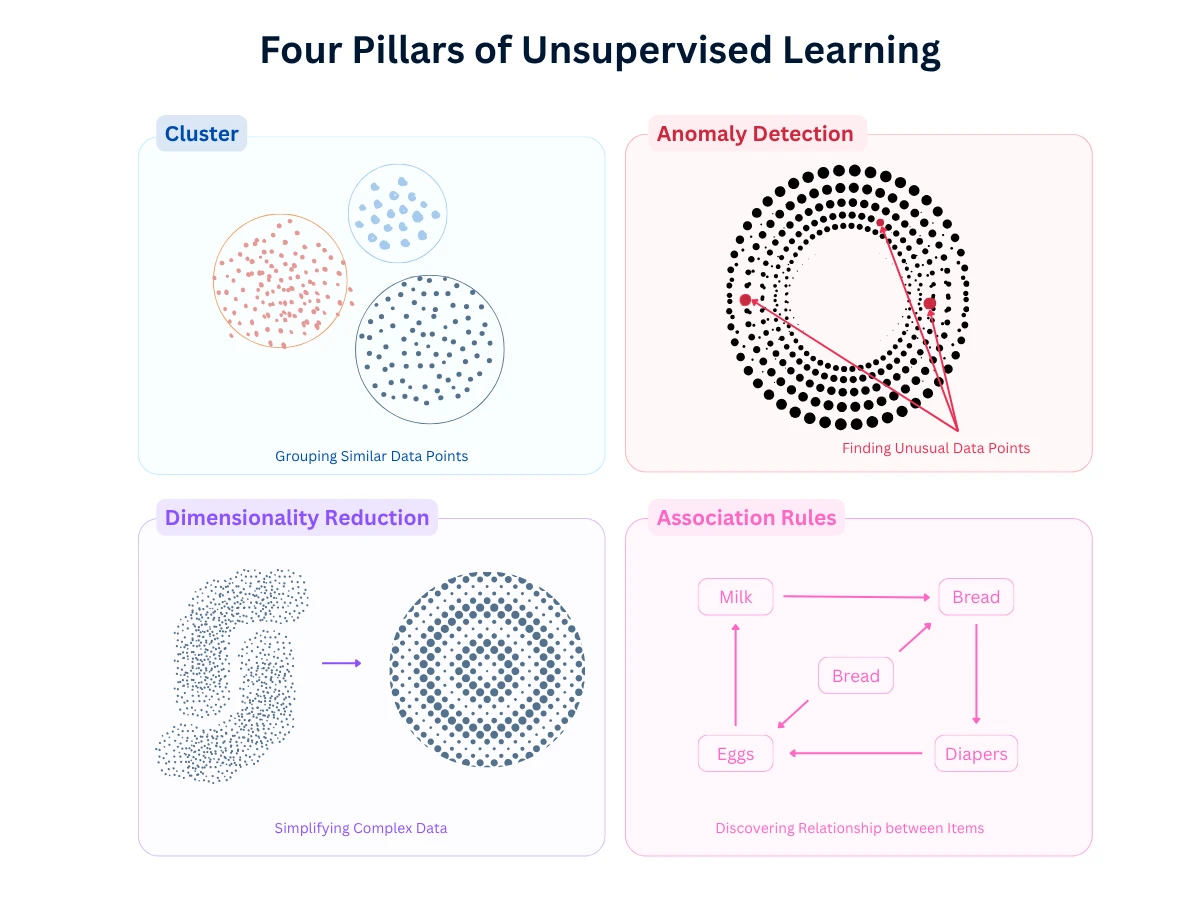
The Four Core Approaches of Unsupervised Learning
Unsupervised learning encompasses four main categories, each solving different types of problems. Understanding when to use each approach is critical for successful implementation.
The Four Pillars of Unsupervised Learning - Each approach solves a distinct type of pattern discovery problem
The Four Pillars of Unsupervised Learning: Strategic Business Applications
Learning Category
Business Question Answered
Strategic Value
Implementation Complexity
Industry Leaders
Clustering
What natural groups exist in our data?
Customer segmentation, market analysis
Medium
Amazon customer personas, Spotify music clustering
Google search ranking, Facebook news feed optimization
Association Mining
What items frequently occur together?
Recommendation systems, cross-selling
Medium
Amazon 'Customers who bought', Netflix content recommendations
Source: Core categories synthesized from Google AI research taxonomy, Amazon Science publications, Netflix Technology Blog methodologies, and industry machine learning conference proceedings (2019-2024)
The Validation Challenge
Unlike supervised learning, unsupervised results cannot be automatically validated. There's no "accuracy score" to confirm the patterns are correct. Success requires combining algorithmic sophistication with deep domain expertise to interpret discovered patterns. This is why validation and interpretation are critical skills for unsupervised learning.
When to Use Unsupervised Learning: Problem Suitability Framework
Not every problem is suitable for unsupervised learning. The critical requirement is having a clear goal for pattern discovery and the domain expertise to interpret results. Here's how to determine which approach fits your problem:
Unsupervised Learning Decision Framework: Matching Problems to Approaches
Your Problem
Recommended Approach
Why It Works
Example Application
Find natural customer groups
Clustering
Discovers segments without predefined categories
Amazon customer personas, market segmentation
Detect unusual transactions
Anomaly Detection
Identifies outliers that deviate from normal patterns
PayPal fraud detection, system monitoring
Simplify complex data
Dimensionality Reduction
Reduces features while preserving information
Netflix user preference compression, data visualization
Find item relationships
Association Rules
Discovers which items frequently occur together
Amazon recommendations, market basket analysis
Explore unknown patterns
Clustering + Visualization
Reveals structures you didn't know to look for
Discovering new customer behaviors, trend analysis
Prepare data for other models
Dimensionality Reduction
Removes noise and redundant features
Feature engineering for supervised learning
Source: Problem-solution mapping documented from practical ML applications and industry best practices
When NOT to Use Unsupervised Learning
Avoid unsupervised learning when: (1) you have labeled data and clear prediction goals (use supervised learning), (2) you lack domain expertise to interpret results, (3) you need objective validation metrics, (4) the cost of incorrect interpretations is too high. Unsupervised learning requires strong domain knowledge to extract value.
Clustering: Discovering Natural Groups in Data
Clustering is the most common unsupervised learning approach. It automatically groups similar data points together without being told what the categories should be. Think of it as organizing your closet by grouping similar items together—shoes with shoes, shirts with shirts—but without any labels telling you what goes where.
In business applications, clustering discovers customer segments, product categories, or market opportunities that weren't obvious from traditional analysis. Amazon uses clustering to group customers by behavior patterns. Spotify clusters songs to create personalized playlists. Netflix discovered thousands of content micro-genres through clustering that drive their recommendation engine.
Why This Visual? Choosing the right clustering algorithm depends on your business need, data characteristics, and scale requirements. This interactive tool helps you select the optimal algorithm for your specific scenario—from Amazon's customer segmentation to PayPal's fraud detection.
5 Algorithms
From partition to graph-based methods
1K - 1M+ Records
Scalability range across algorithms
8 Business Needs
From segmentation to fraud detection
K-Means
Partition-Based
▼
Best Use Case:Customer segmentation with known group count
Scalability:Excellent (millions of records)
Business Advantage:Fast, interpretable results with clear segment boundaries
Implementation Example:E-commerce platforms segment shoppers by purchase behavior, browsing patterns, and lifetime value to drive personalized marketing
Complexity:Low
Hierarchical Clustering
Hierarchy-Based
▶
DBSCAN
Density-Based
▶
Gaussian Mixture
Probabilistic
▶
Spectral Clustering
Graph-Based
▶
Madrigal, A. (2014). How Netflix Reverse Engineered Hollywood. The Atlantic. Documents Netflix's ~76,897 content micro-genres created through content clustering.
Gomez-Uribe, C. A., & Hunt, N. (2016). The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Transactions on Management Information Systems, 6(4). Reports $1B+/year in retention savings from the recommendation system.
PayPal Technology Blog (Medium). Bridging Between Worlds: A Collaborative Story of Data and Decision Science. Describes PayPal's internal use of DBSCAN for fraud cluster detection.
PyData Tel Aviv (2022). Parallelizing DBSCAN over 400 Million PayPal Records. Documents DBSCAN deployment scale at PayPal.
Spotify Newsroom (2025). Discover Weekly Turns 10: 100 Billion+ Tracks Streamed. Reports on scale of Spotify's personalized discovery engine.
Google Developers. Introduction to Clustering - Machine Learning Crash Course. Describes spectral and graph-based clustering for complex pattern detection.
Common Clustering Algorithms: When to Use Which
Algorithm
Best For
Strengths
Limitations
K-Means
Customer segmentation, market analysis
Fast, scalable, easy to interpret
Need to specify number of clusters, assumes spherical clusters
Hierarchical
Taxonomy creation, nested groups
Shows relationships between clusters, no need to specify k
Doesn't scale well, sensitive to noise
DBSCAN
Anomaly detection, irregular shapes
Finds clusters of any shape, identifies outliers automatically
Sensitive to parameters, struggles with varying densities
Gaussian Mixture
Soft segmentation, overlapping groups
Probabilistic cluster assignment
Requires specifying number of clusters, computationally expensive
Source: Clustering algorithm selection patterns documented from industry ML applications and academic research
Deep Dive Available
Want to learn more about clustering algorithms, implementation details, and evaluation metrics? Check out our dedicated Clustering Methods page that covers algorithm selection, hyperparameter tuning, and production deployment strategies.
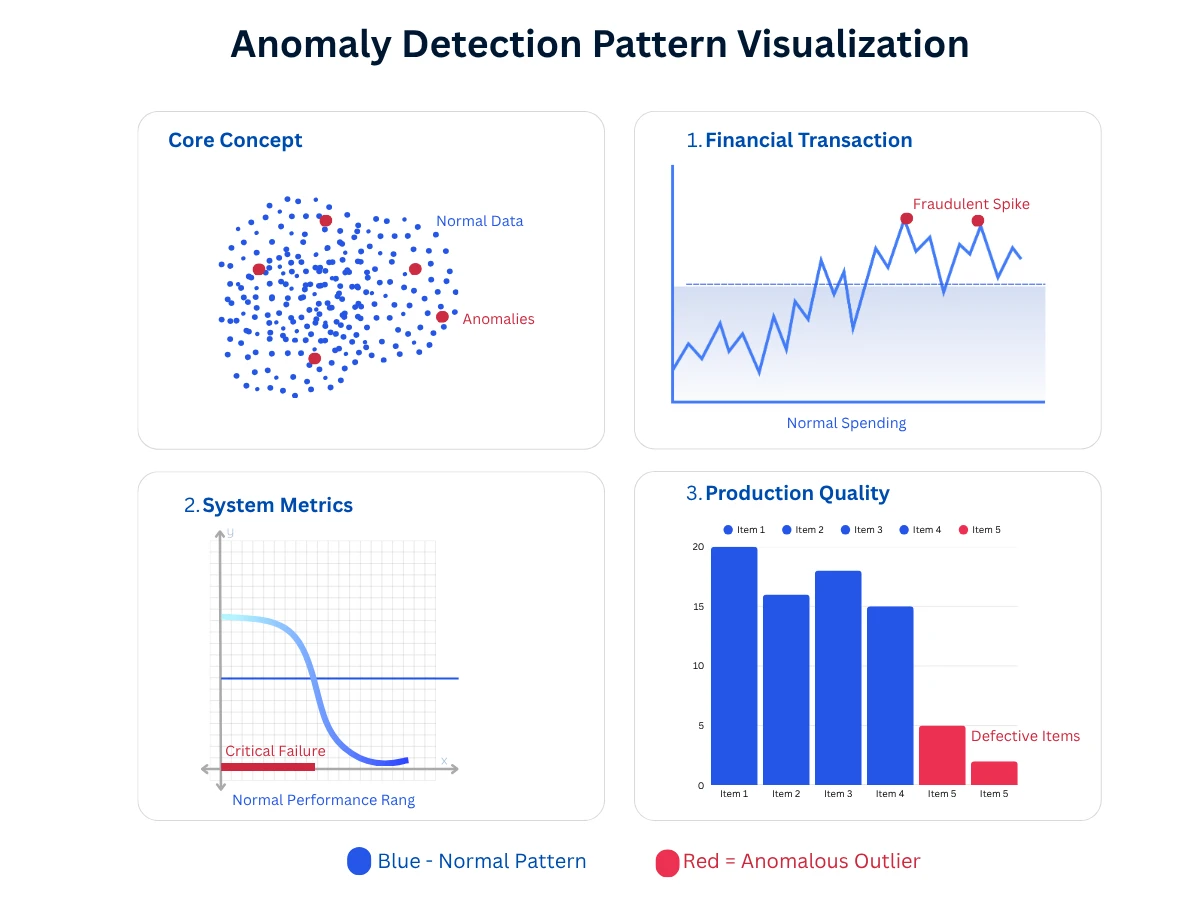
Anomaly Detection: Finding Unusual Patterns and Outliers
Anomaly detection (also called outlier detection) identifies data points that deviate significantly from normal patterns. It's like a security guard who knows what "normal" looks like and alerts you when something unusual happens—whether that's fraud, system failures, or quality defects.
In practice, anomaly detection powers fraud prevention (PayPal blocking suspicious transactions), system monitoring (Netflix detecting streaming issues), quality control (manufacturing defect detection), and even opportunity discovery (identifying unusual customer behaviors that signal high value).
Anomaly Detection Pattern Visualization - Normal behavior forms predictable clusters while anomalies appear as isolated outliers requiring investigation
Common Anomaly Detection Methods
Method
Best For
How It Works
Example Use
Statistical Methods
Simple outlier detection
Flags points beyond normal distribution (e.g., 3 standard deviations)
Fraud detection, quality control
Isolation Forest
High-dimensional data
Isolates anomalies by random splitting (outliers are easier to isolate)
System monitoring, log analysis
One-Class SVM
Learning normal behavior
Learns boundary around normal data, flags points outside
Equipment failure prediction
Autoencoders
Complex pattern anomalies
Neural network learns to reconstruct normal data, fails on anomalies
Cybersecurity threat detection
Source: Anomaly detection methods documented from industry ML applications and research
The False Positive Challenge
Anomaly detection's biggest challenge is false positives—flagging normal events as anomalies. Too many false alarms and humans ignore the system. The key is tuning the sensitivity based on business context: fraud detection can tolerate 1-5% false positives, but medical diagnosis needs much lower rates.
Dimensionality Reduction: Simplifying Complex Data
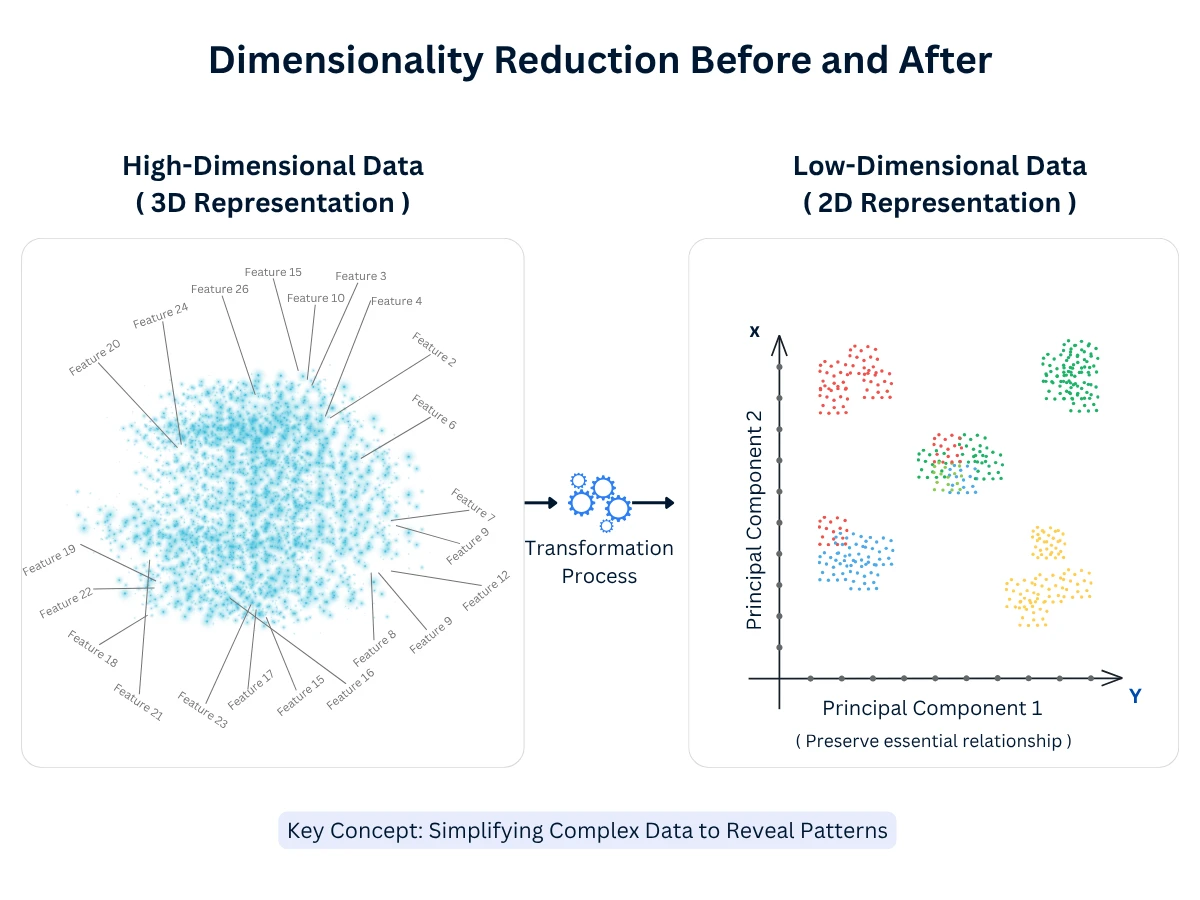
Dimensionality reduction transforms high-dimensional data (hundreds or thousands of features) into lower-dimensional representations (2D or 3D) while preserving the essential information. Think of it as creating a simplified map from complex terrain—you lose some detail but keep the important relationships.
This technique enables visualization of complex data (plot 100-dimensional customer data in 2D), reduces computational costs (faster processing with fewer features), removes noise (eliminate redundant or irrelevant features), and improves other machine learning models (better input features lead to better predictions).
Dimensionality Reduction Before and After - High-dimensional data (left) is transformed into a lower-dimensional representation (right) that preserves essential relationships while enabling visualization
Common Dimensionality Reduction Techniques
Technique
Best For
How It Works
Typical Use Case
PCA (Principal Component Analysis)
Data preprocessing, visualization
Finds directions of maximum variance in data
Reducing features before modeling, data compression
t-SNE
Visualization of clusters
Preserves local structure, emphasizes clusters
Visualizing customer segments, exploring patterns
UMAP
Fast visualization, large datasets
Preserves both local and global structure
Interactive data exploration, embedding visualization
Source: Dimensionality reduction methods from standard ML literature and practical applications
Deep Dive Available
Our Dimensionality Reduction page covers PCA mathematics, t-SNE implementation, choosing the right number of dimensions, interpreting results, and production deployment strategies for different business contexts.
Association Mining: Discovering Item Relationships
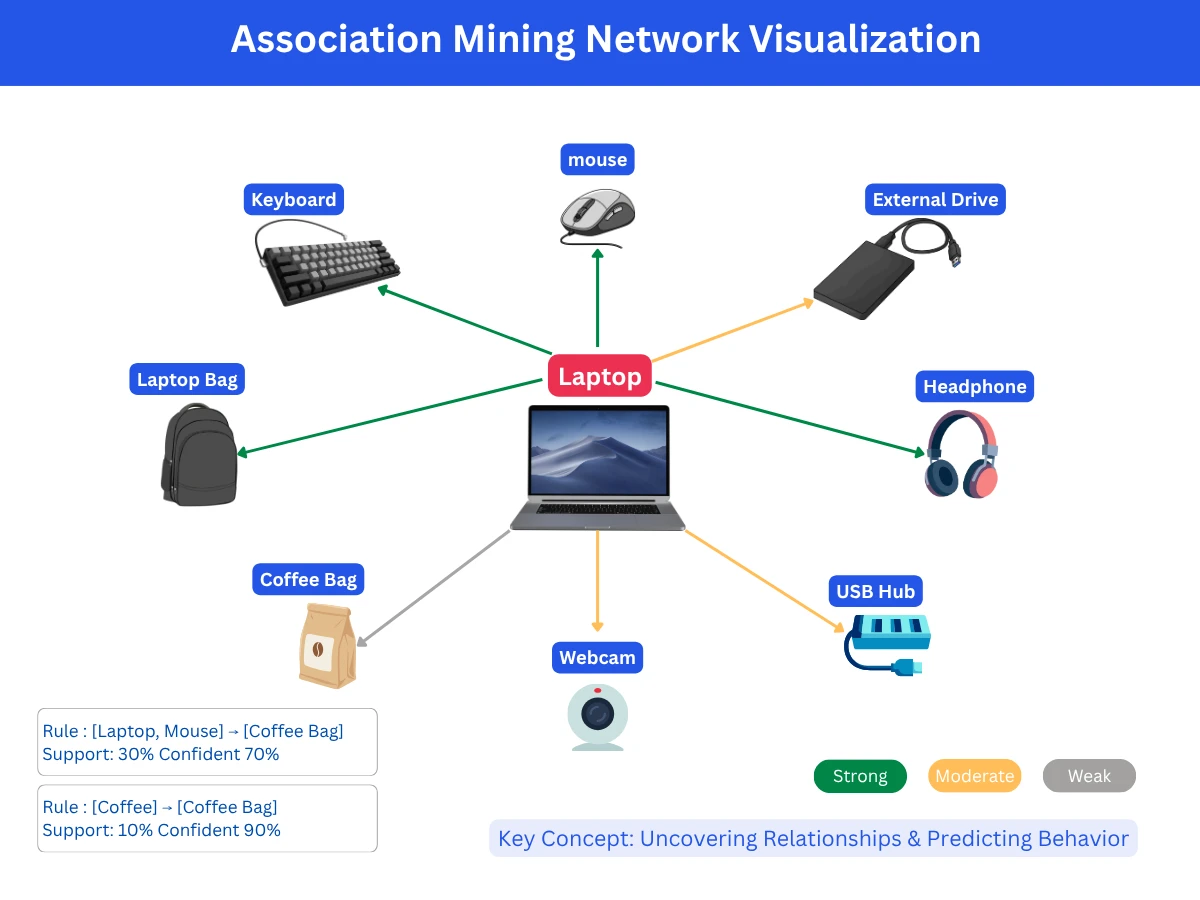
Association rule mining (also called market basket analysis) discovers relationships between items or events in transaction data. The classic example is "customers who bought bread also bought butter," but modern applications go far beyond simple product recommendations to reveal complex patterns in customer behavior, content relationships, and sequential patterns.
Amazon's "Frequently bought together" feature uses association mining. Netflix discovers content relationships to improve recommendations. Grocery stores use it for store layout optimization. The key insight: these relationships emerge from the data itself, revealing patterns that might not be obvious from business intuition alone.
Association Mining Network Visualization - Item relationships discovered from transaction data, with line thickness indicating association strength and support/confidence metrics shown for each connection
Association Mining Applications
Application Type
What It Discovers
Common Algorithms
Example Use
Market Basket Analysis
Items frequently bought together
Apriori, FP-Growth
Product recommendations, store layout optimization
Source: Association mining patterns from e-commerce and recommendation system applications
Deep Dive Available
Our Association Rules page covers the Apriori algorithm, support and confidence metrics, sequential pattern mining, and implementing recommendation systems with real-world case studies.
Common Pitfalls: Top Mistakes That Derail Projects
Analysis of unsupervised learning projects reveals consistent failure patterns. Here are the top mistakes and how to avoid them:
Lack of Domain Expertise: Discovering technically valid patterns that have no business meaning. SOLUTION: Always involve domain experts in pattern interpretation and validation.
Poor Data Quality: Garbage in, patterns out - discovering patterns in noise or biased data. SOLUTION: Establish data quality standards (>95% completeness, representative samples).
Ignoring Temporal Changes: Patterns discovered today may not hold tomorrow - customer behavior shifts, markets evolve. SOLUTION: Monitor pattern stability and retrain models regularly.
Spurious Correlations: Finding coincidental relationships that don't generalize. SOLUTION: Validate patterns across different time periods and datasets before acting.
Scale Underestimation: Algorithms that work on samples fail on full production data. SOLUTION: Test at production scale before deployment.
The 73% Failure Rate
According to Gartner's 2024 analysis, 73% of unsupervised learning projects fail to deliver business value. The primary reason isn't algorithmic—it's the lack of domain expertise to interpret discovered patterns. Include business experts from day one, not just data scientists.
Your Unsupervised Learning Journey: What's Next
Now that you understand unsupervised learning fundamentals, you're ready to dive deeper into specific techniques. Here's the recommended learning path through our unsupervised learning section:
Unsupervised Learning Fundamentals (this page, 16 min): Core concepts, four approaches, when to use each, data quality requirements
Association Rules (12 min): Market basket analysis, Apriori algorithm, support and confidence, recommendation systems
Supporting topics covered in other sections include data preparation (feature scaling, normalization), evaluation strategies (silhouette scores, elbow method), and model deployment. The complete unsupervised learning journey takes about 60 minutes and provides production-ready knowledge.
Frequently Asked Questions
01What's the difference between supervised and unsupervised learning?
Supervised learning uses labeled data (input-output pairs) to predict outcomes. Unsupervised learning works with unlabeled data to discover hidden patterns. Use supervised when you know what you want to predict; use unsupervised when you want to discover unknown structures or groupings in your data.
02Which clustering algorithm should I use?
Start with K-means if you can estimate the number of clusters (fast, scalable, interpretable). Use hierarchical clustering when you want to see relationships between groups (good for small datasets). Choose DBSCAN for irregular shapes or when you need automatic outlier detection. Gaussian mixture models work well when clusters overlap.
03How do I validate unsupervised learning results?
Unlike supervised learning, there's no automatic accuracy metric. Combine technical metrics (silhouette score, inertia) with business validation: Do the discovered clusters make sense? Can domain experts interpret them? Do they lead to actionable insights? Always validate with business experts, not just data scientists.
04How much data do I need for unsupervised learning?
Minimum 100-1000 data points for basic clustering; 10,000+ for production systems. The key is having enough examples to reveal meaningful patterns. Quality matters more than quantity - 1,000 high-quality, representative samples beat 100,000 biased or noisy ones.
05Is unsupervised learning harder than supervised learning?
Technically, algorithms can be simpler. The challenge is interpretation - there's no right answer to validate against. You need strong domain expertise to determine if discovered patterns are meaningful or spurious. Success depends more on business understanding than algorithm sophistication.
06Can I use unsupervised learning with labeled data?
Yes! Many successful applications combine both. Use unsupervised learning to discover patterns first (clustering, dimensionality reduction), then apply supervised learning to those discovered patterns. This hybrid approach often outperforms using either alone.
07What are the main business applications of unsupervised learning?
Customer segmentation (finding natural customer groups), fraud detection (identifying unusual patterns), recommendation systems (discovering item relationships), data compression (reducing features while preserving information), and exploratory analysis (understanding data structure before modeling).
08How long does it take to implement unsupervised learning?
Typical timeline: 8-16 weeks. Data exploration and quality assessment (2-4 weeks), algorithm experimentation (2-3 weeks), pattern validation with domain experts (2-6 weeks), production deployment (2-3 weeks). Simple exploratory projects can be faster; strategic business applications take longer due to validation requirements.
Ready to Dive Deeper?
You now understand unsupervised learning fundamentals and the four core approaches. Your next step is exploring specific techniques in depth based on your problem type.
Your Next Step
Start with Clustering Methods if you want to discover customer segments or natural groupings. Or jump to Dimensionality Reduction if you need to visualize or simplify high-dimensional data. Both pages build directly on the foundations you've learned here.
Unsupervised learning is not about finding patterns in data—it's about discovering opportunities in reality. The companies that master pattern discovery without supervision will discover competitive advantages that supervised learning can never provide.