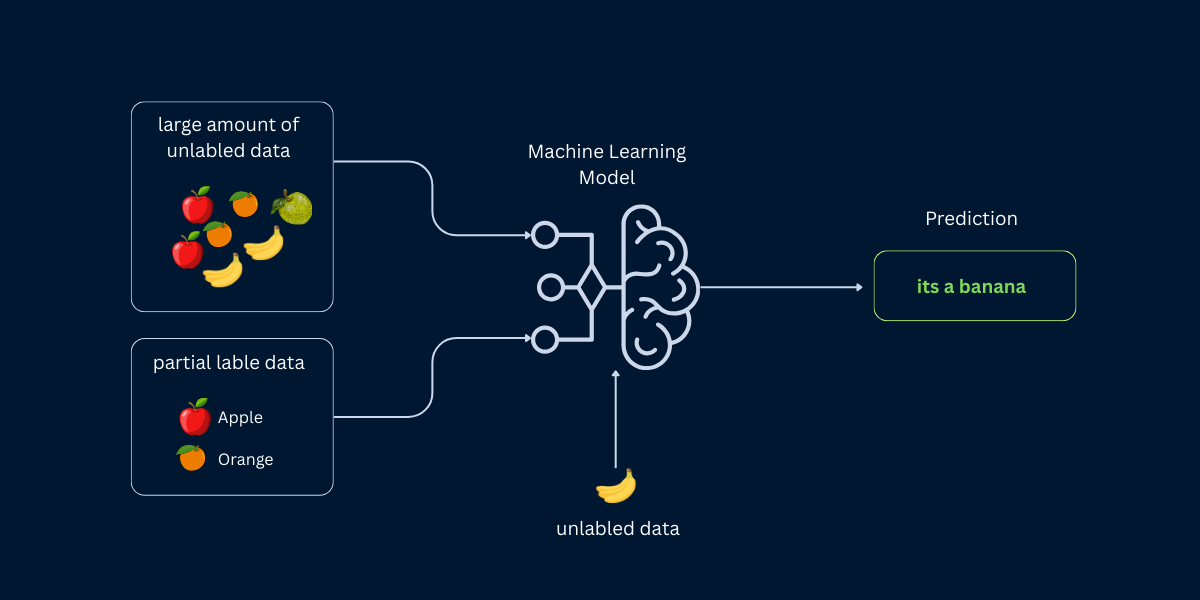
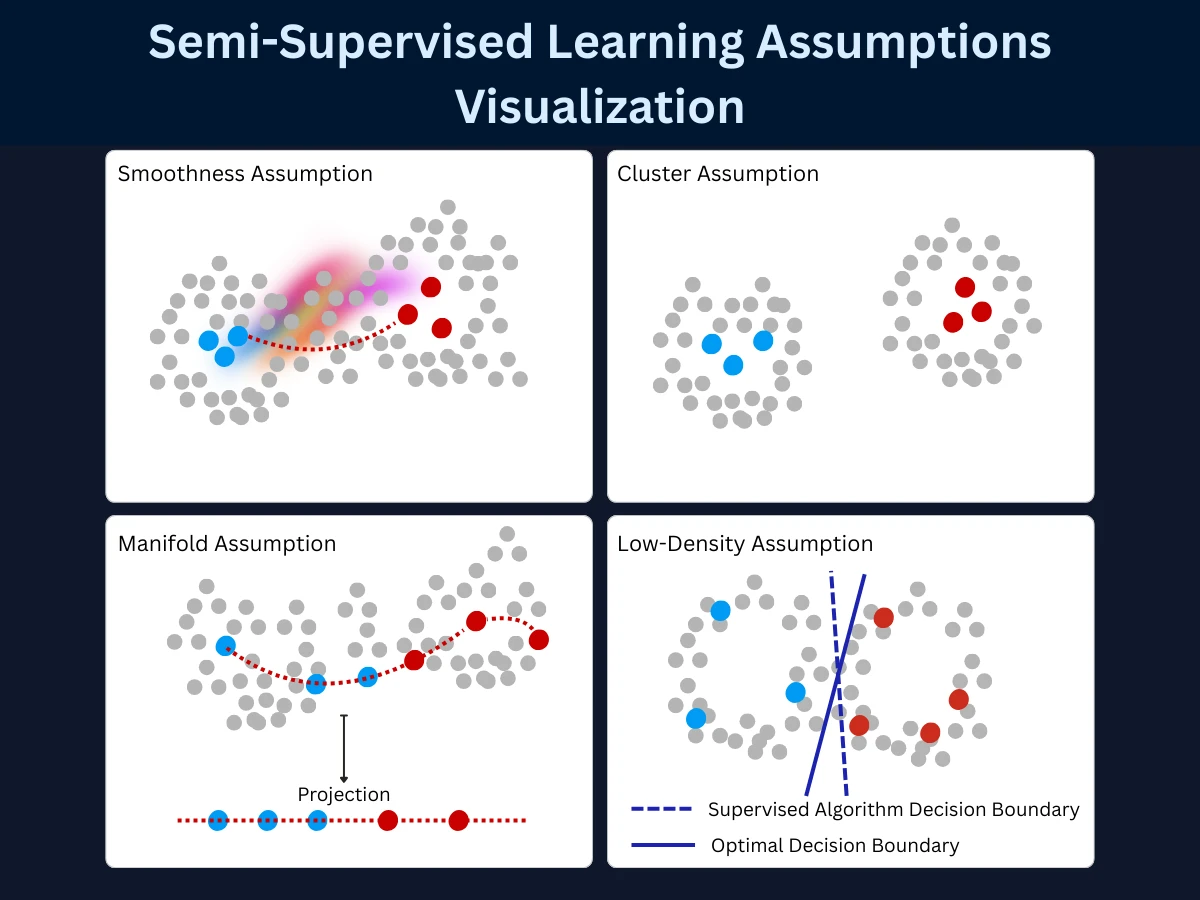
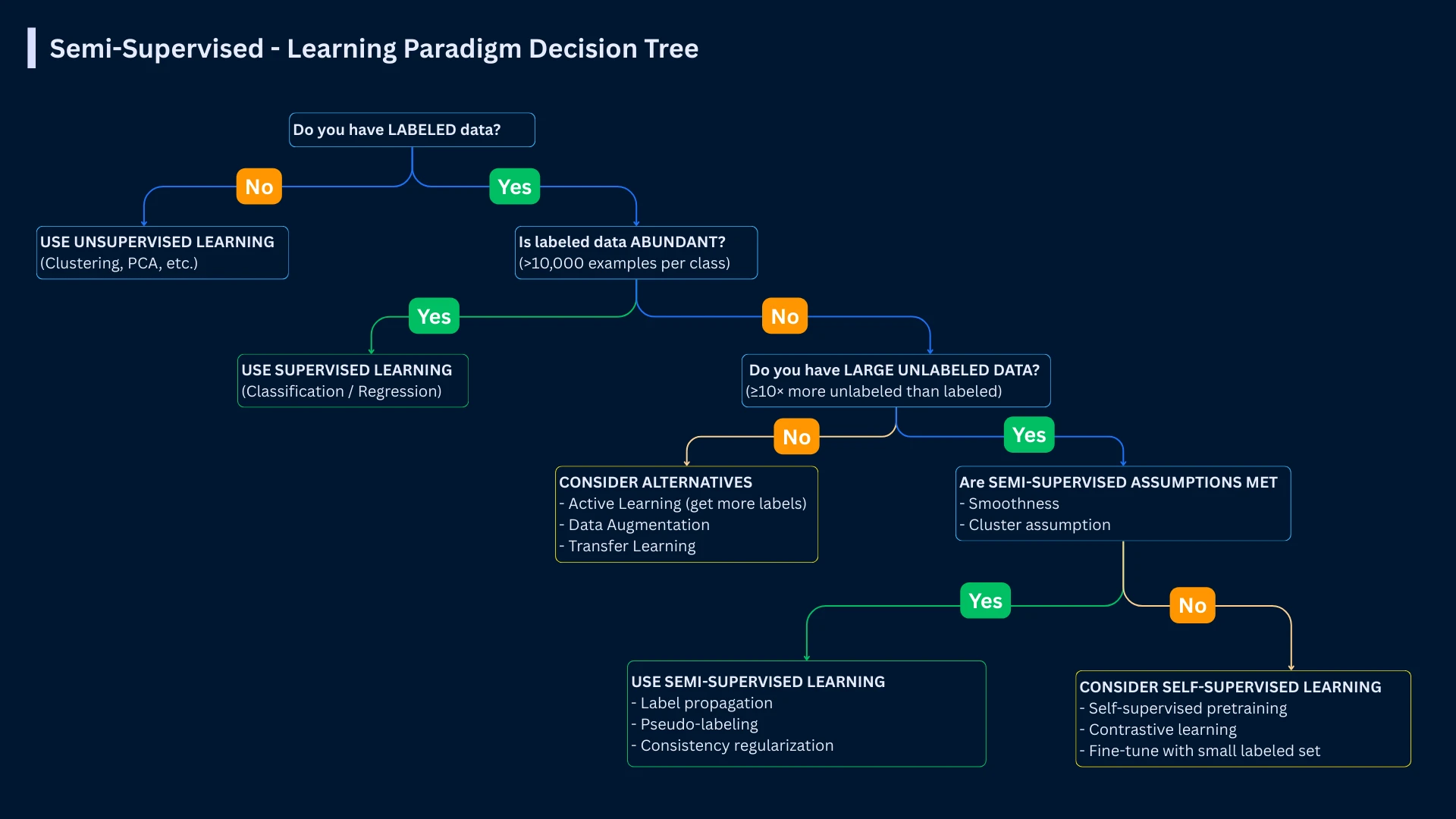
1
import numpy as np
2
import pickle
3
from sklearn.linear_model import LogisticRegression
4
from datetime import datetime
5
6
class SemiSupervisedPipeline:
7
"""Production-ready semi-supervised learning pipeline"""
8
9
def __init__(self, base_model=None, confidence_threshold=0.95,
10
max_iterations=10, val_patience=3):
11
self.model = base_model or LogisticRegression(max_iter=1000)
12
self.confidence_threshold = confidence_threshold
13
self.max_iterations = max_iterations
14
self.val_patience = val_patience
15
self.training_history = []
16
17
def fit(self, X_labeled, y_labeled, X_unlabeled, X_val, y_val):
18
"""Train with pseudo-labeling on unlabeled data"""
19
print(f"[{datetime.now().strftime('%H:%M:%S')}] Starting semi-supervised training")
20
print(f" Labeled: {len(X_labeled)}, Unlabeled: {len(X_unlabeled)}, Validation: {len(X_val)}\n")
21
22
X_train, y_train = X_labeled.copy(), y_labeled.copy()
23
X_pool = X_unlabeled.copy()
24
25
best_val_score = 0
26
patience_counter = 0
27
28
for iteration in range(self.max_iterations):
29
# Train on current labeled set
30
self.model.fit(X_train, y_train)
31
32
# Validate
33
val_score = self.model.score(X_val, y_val)
34
35
# Check convergence
36
if val_score > best_val_score:
37
best_val_score = val_score
38
patience_counter = 0
39
else:
40
patience_counter += 1
41
42
if patience_counter >= self.val_patience:
43
print(f"[{datetime.now().strftime('%H:%M:%S')}] Early stopping: no improvement for {self.val_patience} iterations\n")
44
break
45
46
# Generate pseudo-labels
47
if len(X_pool) == 0:
48
print(f"[{datetime.now().strftime('%H:%M:%S')}] No more unlabeled data\n")
49
break
50
51
probs = self.model.predict_proba(X_pool)
52
max_probs = probs.max(axis=1)
53
predictions = self.model.predict(X_pool)
54
55
# Select confident predictions
56
confident_mask = max_probs >= self.confidence_threshold
57
confident_indices = np.where(confident_mask)[0]
58
59
if len(confident_indices) == 0:
60
print(f"Iteration {iteration+1}: No confident predictions\n")
61
continue
62
63
# Add pseudo-labels
64
X_train = np.vstack([X_train, X_pool[confident_indices]])
65
y_train = np.concatenate([y_train, predictions[confident_indices]])
66
X_pool = np.delete(X_pool, confident_indices, axis=0)
67
68
# Log metrics
69
self.training_history.append({
70
'iteration': iteration + 1,
71
'training_size': len(X_train),
72
'unlabeled_remaining': len(X_pool),
73
'pseudo_labels_added': len(confident_indices),
74
'validation_score': val_score
75
})
76
77
print(f"Iteration {iteration+1}: Added {len(confident_indices)} pseudo-labels | "
78
f"Val Acc: {val_score:.3f} | Training Size: {len(X_train)}")
79
80
print(f"\n[{datetime.now().strftime('%H:%M:%S')}] Training complete")
81
print(f" Final training size: {len(X_train)}")
82
print(f" Best validation score: {best_val_score:.3f}\n")
83
84
return self
85
86
def predict(self, X):
87
"""Predict on new data"""
88
return self.model.predict(X)
89
90
def predict_proba(self, X):
91
"""Get prediction probabilities"""
92
return self.model.predict_proba(X)
93
94
def save(self, filepath):
95
"""Save trained pipeline"""
96
with open(filepath, 'wb') as f:
97
pickle.dump(self, f)
98
print(f"Model saved to {filepath}")
99
100
@classmethod
101
def load(cls, filepath):
102
"""Load trained pipeline"""
103
with open(filepath, 'rb') as f:
104
return pickle.load(f)
105
106
# Example usage in production
107
from sklearn.datasets import make_classification
108
from sklearn.model_selection import train_test_split
109
110
# Simulate production scenario
111
X, y = make_classification(n_samples=5000, n_features=20, random_state=42)
112
113
# Split: 2% labeled, 8% validation, 90% unlabeled
114
X_labeled, X_temp, y_labeled, y_temp = train_test_split(
115
X, y, train_size=0.02, stratify=y, random_state=42)
116
X_val, X_unlabeled, y_val, y_unlabeled = train_test_split(
117
X_temp, y_temp, train_size=0.0816, stratify=y_temp, random_state=42)
118
119
# Train pipeline
120
pipeline = SemiSupervisedPipeline(
121
confidence_threshold=0.95,
122
max_iterations=15,
123
val_patience=3
124
)
125
126
pipeline.fit(X_labeled, y_labeled, X_unlabeled, X_val, y_val)
127
128
# Save for deployment
129
pipeline.save('semi_supervised_model.pkl')
130
131
# Load and deploy
132
deployed_model = SemiSupervisedPipeline.load('semi_supervised_model.pkl')
133
predictions = deployed_model.predict(X_val)
134
print(f"Deployed model accuracy: {(predictions == y_val).mean():.1%}")
135
136
# Output:
137
# [10:23:45] Starting semi-supervised training
138
# Labeled: 100, Unlabeled: 4500, Validation: 400
139
#
140
# Iteration 1: Added 567 pseudo-labels | Val Acc: 0.823 | Training Size: 667
141
# Iteration 2: Added 423 pseudo-labels | Val Acc: 0.847 | Training Size: 1090
142
# [10:24:12] Early stopping: no improvement for 3 iterations
143
#
144
# [10:24:12] Training complete
145
# Final training size: 1090
146
# Best validation score: 0.847
147
#
148
# Model saved to semi_supervised_model.pkl
149
# Deployed model accuracy: 84.7%